SOTA RAG Series
This is the first blog in our series building a state-of-the-art retrieval
augmented generation SOTA RAG pipeline. You can read up on the full series here:
Today we are announcing a new blog series called state-of-the-art (SOTA) retrieval augmented generation (RAG), SOTA RAG for short. Retrieval augmented generation has been all over the web in the last couple of months and despite some nay-sayers, it is here to stay.
While large language models (LLMs) are great tools they still do have quite a few flaws among which are hallucinations and retrieval issues. Both these issues are resolved with RAG. This blog post series explores how RAG systems excel at finding relevant documents and providing accurate answers to user’s questions.
But, as we said before, RAG is not new, every self-respecting AI company has a blog about it. Why should you bother reading ours over any of the thousands of blogs out there on the internet?
Most implementations, RAG examples, and blogs don’t go much further than the “cute demo on a laptop phase”. They use a couple of hundred PDFs (if even that many), create embeddings, store them in a vector database and implement a simple KNN-based retriever to answer user questions using similarity search.

While this creates a compelling demo, it’s a far cry from what a production-level RAG pipeline looks like.
In the sections below we discuss the required elements for a full-scale SOTA RAG pipeline. In the coming weeks, we dedicate six additional blog posts to the topic diving into much more detail, by the end of it you have the required background knowledge to build such a pipeline yourself.
There is no denying building a SOTA RAG pipeline is complex (trust us we have done it many times), to a large extent, it comes down to building an effective search pipeline and search is hard.
Our team is here to help! whether you want to pick our brains for 30 minutes during a free consultation call, or want us to build the full-blown pipeline, don’t hesitate to reach out.
Allow me to introduce Lost Minute Travel!
To provide a good sample we are building a travel chatbot, tasked with providing travel recommendations for users. Including answering questions, finding flights, and providing real-time data from multiple data sources. The RAG application should learn about the user over time, making better and better recommendations tailored to the user’s request.

To make it a realistic scenario we are implementing the complete lifecycle of an application — allowing the operators to update data, maintaining multiple versions of the data sources, and allowing users to submit GDPR deletion requests and much more.
A SOTA RAG system has many components but can be broken down into the following high-level concepts:
As said before, in the next few weeks we are diving into much more detail on each of these elements including the various models, data stores, and compute infrastructure used. We will share a high-level architecture and system design and give you all the relevant background information needed to build a similar-style system on the Cloudflare network.
Having said that let’s have a quick look at these three high-level concepts and what you can expect in the blogs to come.
The indexer, as one might suspect, is responsible for ingesting information and indexing it into various data sources. To build a SOTA RAG system you need much more than just a vector database. For example, our indexer specifically handles text data, images, tabular, documents and web data.
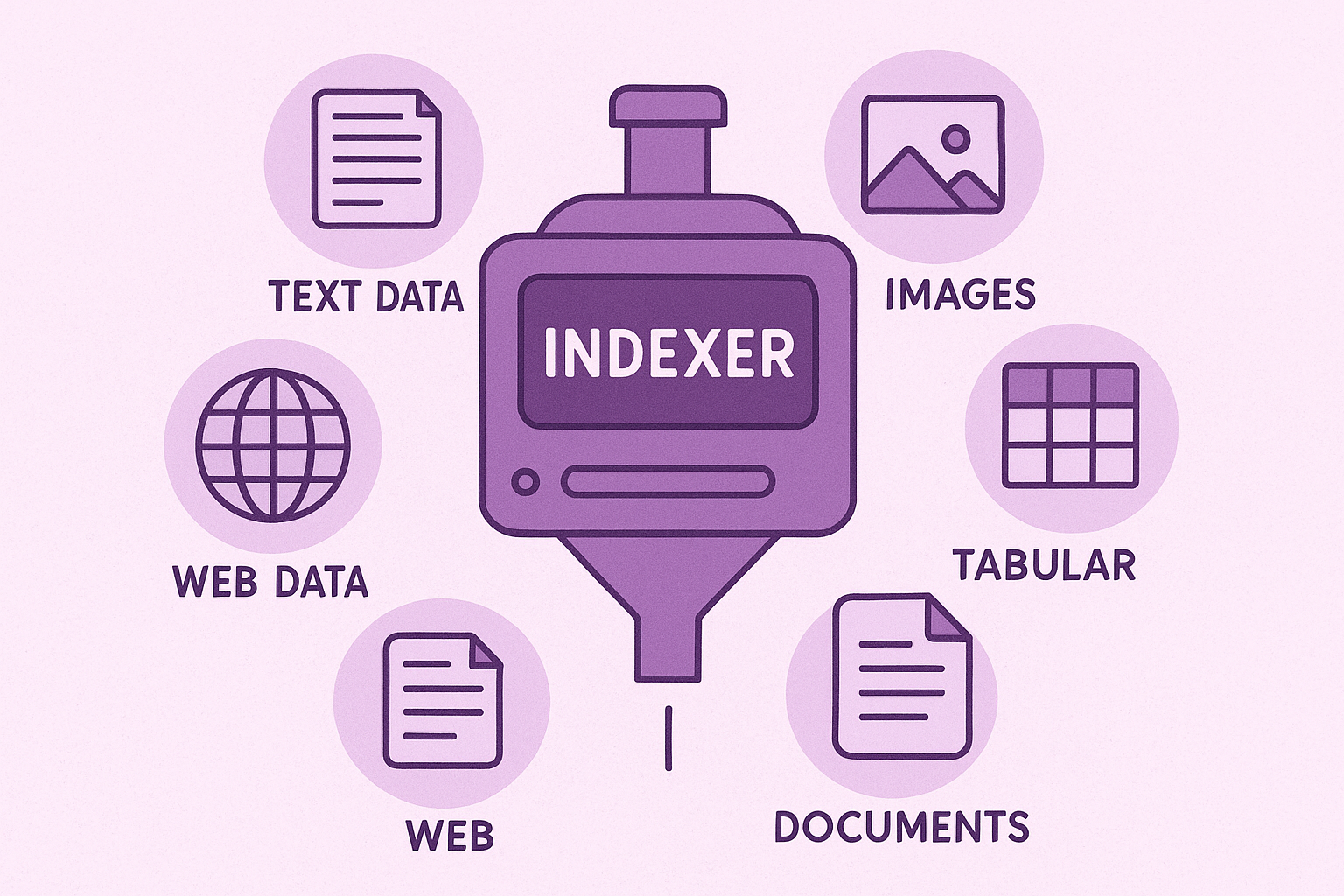
This requires a set of specialized data stores. For our example, we are using various data stores such as a Vector Database (Cloudflare Vectorize), text search (Typesense), a GraphDB (Neo4j), and tabular search (Cloudflare D1). In addition, we store metadata in SQL (Cloudflare D1) and an object store (Cloudflare R2).
We are running the whole system at scale and are indexing the entire English Wikipedia (22 million articles). An observant reader might ask: “Why index all of Wikipedia?”, “Isn’t every LLM model already trained on that data?” The answer to both is yes, but as mentioned before while LLMs have made great progress in the last couple of months they still perform pretty poorly on relevant retrieval, hence the need for RAG. This is a sentiment likely shared with OpenAI considering their recent acquisition of Rockset a platform purposefully built for better retrieval.
In the next edition of this series, we are taking a deep dive into the various data stores we selected for this project with more details on the above. Stay tuned.
Any RAG-based application is as good as its components, and that is specifically true for the retriever. Search is everything, and search is hard. It’s not a coincidence that one of the world’s most valuable companies in its core is a web search company (Google).
The retriever of our SOTA RAG application combines a multitude of techniques to retrieve the most relevant data, optimizing the retrieval process to deliver high-quality relevant results.
Without going into too much detail (we will leave that for a future blog) it assumes the input from the user is poor; after all, this is a chat app so we can’t expect much more than a single input query.
From here on out we use multiple LLM calls to create an answer. First, we have one LLM model hallucinate a few different versions of the question, and we use these as the real input into the pipeline. We then deploy a combination of keyword search in a graph database, text search through Typesense, vector search using Cloudflare Vectorize and various other techniques to retrieve relevant documents from our knowledge bases.
The result is an overwhelming amount of data, way too much to feed into an LLM to answer the question. We use various ranking and scoring methods using LLMs and other AI models to trim down and rank the retrieved information and feed only the most relevant information into the final LLM call to answer the user’s question.
This probably leaves you with more questions than answers right now, which is completely understandable. Keep an eye on our blog in the next couple of weeks. You can expect an in-depth blog post detailing the ins and outs of retrieval shortly.
The cognitive layer or user interaction layer handles all the user interaction in the RAG architecture. A retrieval system as described above isn’t exactly known for its speed. In chat-related environments, a user typically expects a response in under 50ms. A number that is far out of reach considering most LLM calls take longer than that and this retriever has many.
So how do you deal with that? In comes the cognitive architecture. It handles the user’s request and provides an LLM-powered chat component that keeps the user busy by asking clarifying questions and loading relevant data such as flight and weather data in our example.

The chatter between the user and the cognitive layer isn’t just to waste the user’s time, the questions and answers the user provides are used in the ranking step in the retriever architecture to better filter the retrieved information for a more precise retrieval.
More on this in a future blog in the series!
While fine-tuning LLMs on domain-specific data can improve performance, retrieval augmented generation offers a more flexible and scalable approach for many applications. Unlike fine-tuning, which requires retraining models with specialized training data, RAG allows models to access external knowledge dynamically, making it ideal for applications that need up-to-date information or specialized domain knowledge.
Our SOTA RAG approach demonstrates how to get the benefits of specialized knowledge without the computational expense and complexity of continuous model fine-tuning. This approach is particularly valuable for RAG applications that need to incorporate new data regularly through semantic search techniques.

If you can’t wait to get started, we are here to help. Schedule a free consultation with our expert AI team. We are more than happy to share our learnings with you.
You can book time on our calendar here.
Here are some of the most common questions we receive about retrieval augmented generation and RAG systems:
Traditional large language models (LLMs) rely solely on their training data and have a fixed knowledge cutoff date. They cannot access new information or specific domain knowledge unless retrained or fine-tuned. This often leads to hallucinations or outdated responses.
RAG applications, on the other hand, combine LLMs with dynamic retrieval from external data sources. When a user’s question is received, the system retrieves relevant documents or information from its knowledge bases before generating an answer. This approach significantly reduces hallucinations and enables access to up-to-date information without requiring constant model retraining.
RAG systems excel at integrating multiple data sources through specialized indexing techniques. For unstructured data like documents, websites, or text data, the system typically:
When handling structured data, RAG architectures can incorporate traditional databases alongside vector stores, allowing for hybrid retrieval that combines semantic search with precise metadata filtering for optimal performance.
Basic RAG implementations typically use simple vector search to find relevant documents based on embedding similarity. A state-of-the-art RAG system incorporates several advanced techniques:
These sophisticated approaches significantly enhance retrieval performance and response generation quality compared to basic RAG implementations.
Fine-tuning an LLM requires extensive domain-specific training data, computational resources, and creates a new model version that must be managed and deployed. While effective for certain use cases, fine-tuning becomes impractical when information changes frequently or when dealing with large knowledge bases.
RAG provides a more flexible alternative for domain knowledge integration:
Many production systems use a combination approach: a lightly fine-tuned model for domain-specific language patterns with RAG for access to detailed, up-to-date information.
Building RAG systems that work well in production environments presents several challenges:
Scaling retrieval performance: Maintaining low latency when searching through millions of documents requires sophisticated indexing, caching, and query optimization.
Context window limitations: LLMs have fixed context windows, so retrieved information must be carefully selected and prioritized to fit within these constraints while providing sufficient context.
Data freshness: Implementing efficient pipelines to continuously update indexed content when source documents change.
Evaluation complexity: Assessing RAG quality requires measuring both retrieval accuracy and response generation quality, which is more complex than evaluating either component alone.
Handling diverse query types: A single retrieval strategy rarely works optimally for all query types, requiring hybrid approaches and query-type detection.
Model serving costs: Managing compute resources efficiently when deploying multiple AI models for embedding, retrieval, and generation.
Security and compliance: Implementing proper access controls, tracking data provenance, and ensuring GDPR compliance for user data and queries.
Our SOTA RAG approach directly addresses these challenges through a comprehensive architecture designed for real-world applications at scale.