SOTA RAG Series
This is the second blog in our series building a state-of-the-art retrieval
augmented generation (RAG) pipeline. You can read up on the full series here:
In this blog post, we are covering all the various data stores used in our state-of-the-art retrieval augmented generation (SOTA RAG) systems. We fully realize you want us to get into the nitty-gritty of building the indexer, retriever and cognitive architecture part of the application as those are by far the most complex and interesting pieces of any RAG application. We do however want to spend some time discussing the underlying technologies that power this application. Specifically, the data sources, since any RAG application is only as good as its data.
As mentioned in the first edition of this series our goal is to build this entire cloud-native application on Cloudflare’s infrastructure. This means that in most cases we use the available Cloudflare data stores such as Vectorize for vector databases, D1 for SQL database storage, and R2 as our object store. We only branch out to other technologies if no Cloudflare offering is available.

Many of today’s retrieval augmented generation (RAG) demos index text data from PDF files. These demos are great starting points; however, they only scratch the surface of what is possible when building robust RAG architectures that can process large amounts of unstructured data.
For example, imagine our demo application Lost Minute Travel. It takes in images, PDF files, webpages and Wikipedia archives (zim format). It then converts these higher-level data entries into its core components such as:
Each of these types of data needs specific storage optimized for retrieval latency. The retrieval process or query latency sits on a direct path between user queries and results and therefore we have to minimize it as much as possible for the best possible user experience. This blog aims to lift the curtain on the underlying data store technology used in RAG systems.
In our next blog, we’ll dive deeper into the process of ingesting data to create vector embeddings. Stay tuned and follow us on LinkedIn to be notified when it’s released.
The Demo Application
Lost Minute Travel is our demo application. It offers users a convenient chat
interface to plan their ideal vacation. Lost Minute Travel uses a combination of
input data to provide the best possible travel advice. This includes data mined
from travel brochures, Wikipedia pages, travel blogs, and more.
Our retriever (which we will discuss in edition four of this blog series) has access to many different data stores to most effectively search all available information. Since we are dealing with language models all data is eventually converted into text including web pages, images (image descriptions), PDF files and other documents.
A new technique that has gained popularity in the machine learning world is semantic search using vector embeddings. It allows you to find relevant pieces of text based on an input query. Vector databases do so by calculating the Euclidean distance (or other distance measures) to find the nearest neighbors in the vector space, allowing the system to retrieve the most relevant information even when exact keyword matches don’t exist.
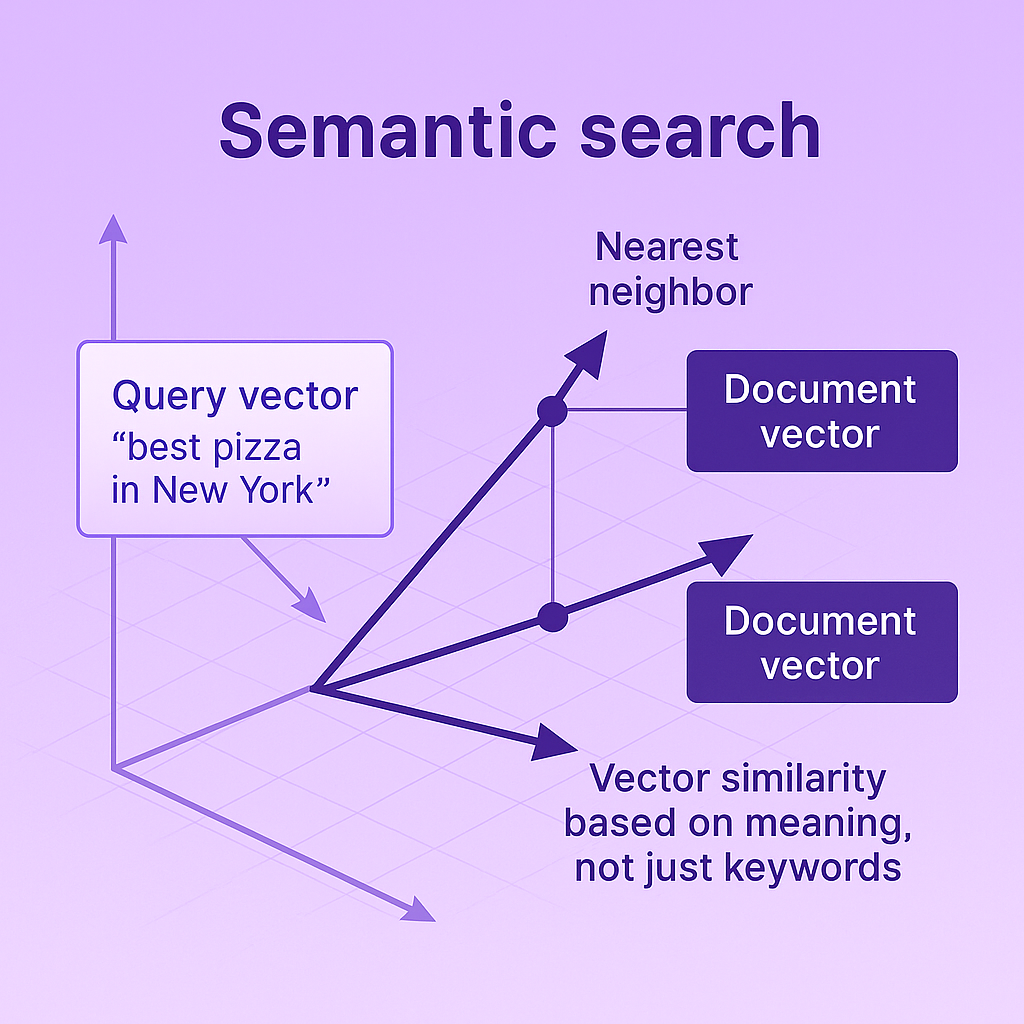
For our vector data, we selected Cloudflare Vectorize as our vector database. We embed all text data into vector representations using bge-base-en-V1.5, creating high-quality text embeddings that accurately capture the semantic meaning of our documents.
One of the reasons we picked Cloudflare as the main cloud provider is its global reach and excellent performance with load balancing capabilities. In our initial tests, we measured the following results for inserting new vectors into the vector database:
While these numbers are ok, we are mostly concerned with retrieval latency rather than insert latency. Retrieval latencies directly influence the perceived performance by the end users when they submit queries. We measure an average latency of ~450 MS for retrieving 20 vectors on an index set up with cosine similarity as the measure for closeness. We did not measure any meaningful difference between retrieving one or 20 vectors i.e. k=1 has the same result as k=20.
These numbers are good but not yet great for high-performance RAG systems. Luckily Cloudflare has already announced that in V2 of the Vectorize beta, the read and write speed is going to be improved.
Since the product is still in beta it has one more significant drawback. It currently only supports 200K vectors per index. This poses a significant challenge for us since the Wikipedia dataset alone consists of 21 million entities.
Cloudflare in a recent Discord post announced they are increasing the limit to 2 million vectors per index. This sounds like a lot but for any standard RAG application that is still fairly limited. For example, our demo app takes ~20 million Wikipedia entities as input. Let’s assume every entity turns into ~5 vectors on average for the text content. That comes down to ~100 million vectors and that does not yet include images converted to text and other higher-level data sources that are eventually stored as vectors.
For our demo app that means we are forced to store vectors across multiple indexes. This has the potential to significantly increase latency as we have to query multiple vector databases at once. Additionally, the total number of vectors we can store is still limited to 200 million (100 vector indexes * 2 million vectors).
We certainly hope Cloudflare will further increase limits in the short term to better support SOTA RAG architectures, but for now, we will make do to take advantage of the great integration between Vectorize and the Cloudflare worker architecture.
Our ingest pipeline needs a place to store - well everything. Our data comes in many forms from text to images to PDF files. The wide variety of data types makes an object store the obvious choice for storing unstructured data. Cloudflare has an object store offering known as Cloudflare R2; this will be our data lake where we store and retrieve large amounts of data for our RAG system.
All data objects including the original input data and all intermediate derived versions of the data are stored in the data lake. For example, imagine a Wikipedia page going through our indexer pipeline. The indexer breaks a single page into multiple components including the original input, HTML data, text data, images and tables. Each of these elements is individually stored in Cloudflare’s R2 buckets, allowing our system to retrieve and process them as needed.
This allows us to keep track of all the data at every step in the pipeline including multiple versions of the same data over time, which helps us maintain accurate information and provide external knowledge to our language model.
Similar to the other data stores R2 offers great performance and price. In our tests, R2 showed 300 MS for reads and 400 MS for writes for a 100KB PDF file.
Additionally, it is very competitively priced. We calculated that the entire storage for a single dataset version of all our input data comes down to $1.50 a month. This includes all images derived from 21 million Wikipedia pages.
Our demo application needs a relational database for two main reasons. We need a place to store directly provided tabular data as well as tabular data derived from higher-level data sets, which enables our system to generate responses with structured information.
Additionally, since this is a SOTA RAG application as close to real life as possible we need a data store for metadata such as data source, dataset version, data signature, and other relevant metadata. This enables data lineage, cycling data sources and more (more on that in a later blog post).
First, let’s look at the ingest requirement. We store tabular data that is either directly provided by users as a CSV or is derived from high-level data sources. For example, 1 in 5 Wikipedia pages have a table on it that contains potentially relevant information for answering user queries.
Tabular data is about as old as the computer itself and the options for storage are plentiful. We chose Cloudflare’s SQL option known as D1 as our primary database. Like many other Cloudflare products D1 is blazingly fast when creating and inserting data. Our initial measurements showed ~0.200 MS for any operation i.e. creating and deleting tables as well as reading and writing data.
In addition, D1 storage is relatively cheap compared to its competitors. Our rough math for our demo application came down to a total of $15 per month for D1 storage. This includes all data derived from Wikipedia which should be about 5 million tables totalling roughly 50GB of data.
D1 has one downside. Similar to vectorize the basic limits are quite low. For example, a standard Cloudflare account has a 250GB max storage limit per account and does not support databases over 10GB. Our application will deal with that by storing data across multiple databases potentially at the cost of latency.
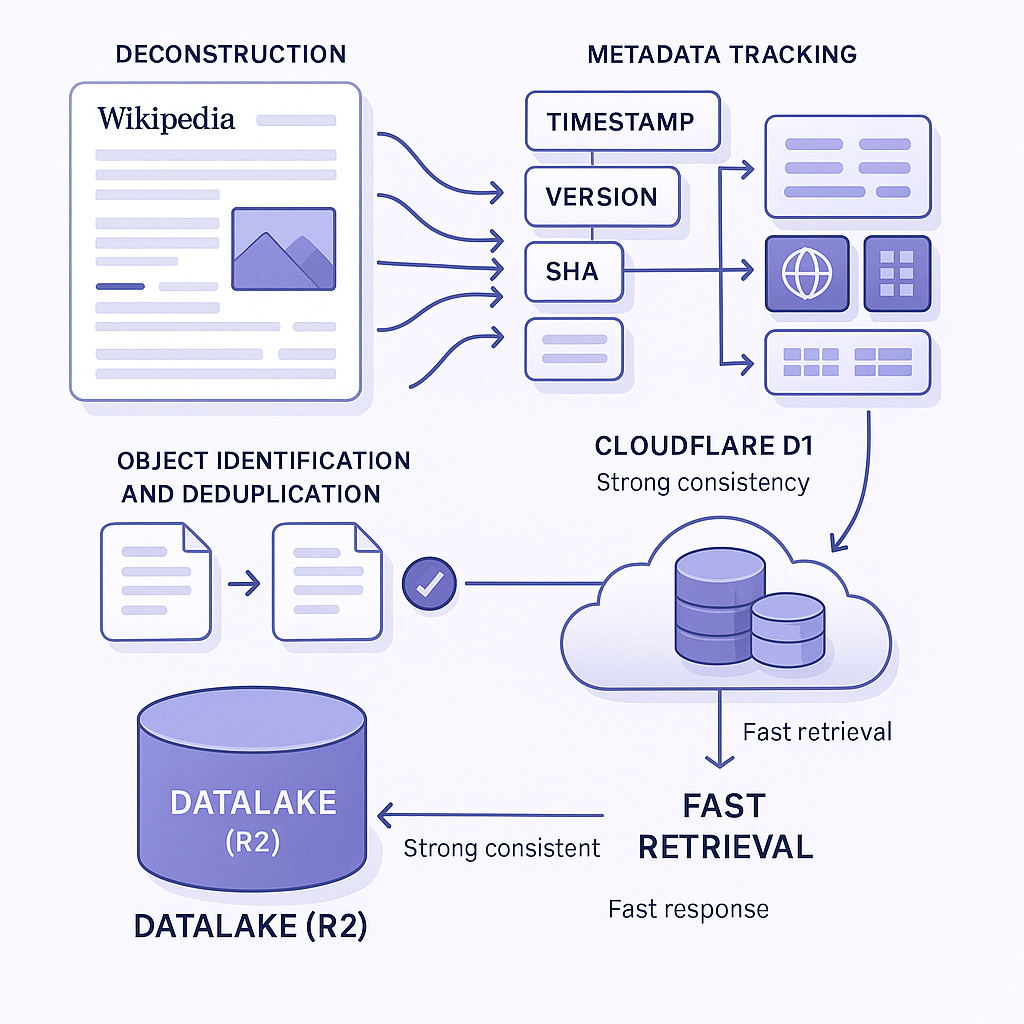
Our indexer deconstructs various input data items into separate components. For example, a Wikipedia page is deconstructed into text, web, images and tables. In our system, we need to keep track of the origin of each element as well as keep track of relevant metadata and dataset versions.
Metadata is crucial for many reasons. For example, we might want to provide the source of the information to our users. Additionally, it’s invaluable for the retriever and indexer components. For each object in our Datalake (R2) we maintain a record of when it was generated, relevant metadata, a data set version and a SHA of the object itself to allow us to easily find and/or discard duplicates.
All this relational data is stored in Cloudflare’s D1 service. The fast responses across multiple tables and strong consistency of D1 is a natural match for metadata in RAG systems that need to access and retrieve context quickly.
LLMs are text-based models and as such text data is one of the most important data types in our application. Every single input data is ultimately converted into text either during indexing or during the retrieval step, requiring robust full text indexes.
Cloudflare as of today does not offer a text search product. As such, we had to broaden our search and landed on the defacto standard open-source full text search known as Typesense.
We provide our retriever with various ways to find the most relevant information including a vector search as detailed above. Additionally, full text search through Typesense allows the retriever to search based on topics. The indexer extracts topics based on each text chunks and stores this data in Typesense, enabling fast and accurate question answering capabilities.
All previous data sources allow the retriever to find data that is directly related to the input query of the user i.e. topic search, cosine similarity etc. Whilst a good start, by just retrieving directly related text chunks we likely are missing a lot of relevant context that could help generate nuanced responses.
We can solve this by mapping and retrieving data by looking at the relationships between the text chunks or more specifically by looking at the relationships of the entities mentioned in the text chunks.
For example, imagine we have an input query related to George Washington. Most data retrieval techniques will only find text chunks directly related to George Washington (or other input query data). However, in doing so we might be ignoring relevant input data such as information about his wife, place of birth and anything else that has a relationship to George Washington. We can capture this information by representing the relationship between entities (George Washington) and the data (text chunks). This allows us to cast a much wider net of potentially interesting data (more on how we do this in the next blog post). Simply said we can retrieve text chunks that either have a direct or indirect relationship to George Washington, providing the most pertinent information for machine learning models to use.
George Washington → President of the United States → Joe Biden
Cloudflare does not have any known offerings for Graph Data which meant we had to look outside their ecosystem for a solution. The defacto industry standard for graph databases is Neo4J, which we selected for our project.
With that, we covered all the data stores we use in our SOTA RAG systems. While perhaps not the most invigorating topic we wanted to create a solid baseline understanding of the various data stores before moving on to more interesting topics such as the indexer and retriever pipelines.
Follow us on LinkedIn to stay up to date on the latest blog posts and developments, or https://calendar.app.google/cjxbyrtmihduPpPt5 to get started on your RAG pipeline today.
A comprehensive RAG system typically requires several types of data stores: vector databases for semantic search capabilities, object stores for raw document storage, relational databases for structured data and metadata, full text search for keyword-based queries, and graph databases for entity relationships. Each plays a crucial role in delivering accurate and relevant information in response to user queries.
Different data types have different access patterns and query requirements. Vector databases excel at similarity searches but fall short for exact keyword matching. Full text search engines excel at keyword searches but don’t understand semantic meaning. Using specialized data stores optimizes performance for each data type, creating a system that can retrieve information through multiple complementary methods.
Traditional text search relies on keyword matching and indexes, requiring exact or fuzzy text matches to find relevant documents. Vector databases use vector embeddings that capture semantic meaning, allowing the system to find conceptually similar content even when keywords don’t match. This enables more natural language understanding and ability to retrieve relevant information based on meaning rather than just keywords.
Retrieval latency is critical since it directly impacts user experience - lower latency means faster responses. Storage capacity limits affect how much data you can index. Write performance affects ingestion speed but is less critical than read performance. Cloud-native solutions often provide better scaling options but may have platform-specific limitations. The right balance depends on your specific application requirements and expected query patterns.
The storage architecture directly impacts what information the language model can access and how quickly it can retrieve relevant context. Well organized data stores with multiple retrieval methods (semantic search, full text search, graph traversal) provide more comprehensive context, enabling the model to generate responses with more accurate, nuanced, and complete information. Poor storage architecture can lead to missing context, irrelevant information, and ultimately lower quality answers.