SOTA RAG Series
This is the fifth blog in our series building a state-of-the-art retrieval
augmented generation SOTA RAG pipeline. You can read up on the full series here:
In this fifth edition of our state-of-the-art Retrieval Augmented Generation (SOTA RAG) blog series, we explore the concept of modeling the human brain, also known as cognitive architectures. If you remember your Human Cognition 101, you’ll see how these ideas tie into modern RAG-based systems.
But before we continue, let’s clarify what cognitive architectures are and how they fit into SOTA RAG applications. The AI industry evolves rapidly, with new terms and technologies appearing almost weekly. You may have heard the buzz around agent-based systems for chatbots — cognitive architectures represent the next step in this progression.
Agent-based systems typically follow a linear, goal-based decision-making process (e.g., Step A leads to Step B). For instance, voice assistants like Alexa and Siri operate as agent-based systems: “Hey Siri, turn on the lights” -> Lights are turned on. Cognitive architectures, on the other hand, implement a more heuristic approach. By incorporating elements that mimic the human brain, these systems allow chatbots to act more autonomously. This gives them the flexibility to respond more naturally to prompts and carry on conversations, even when the user veers off topic. We’ll explore this further below.
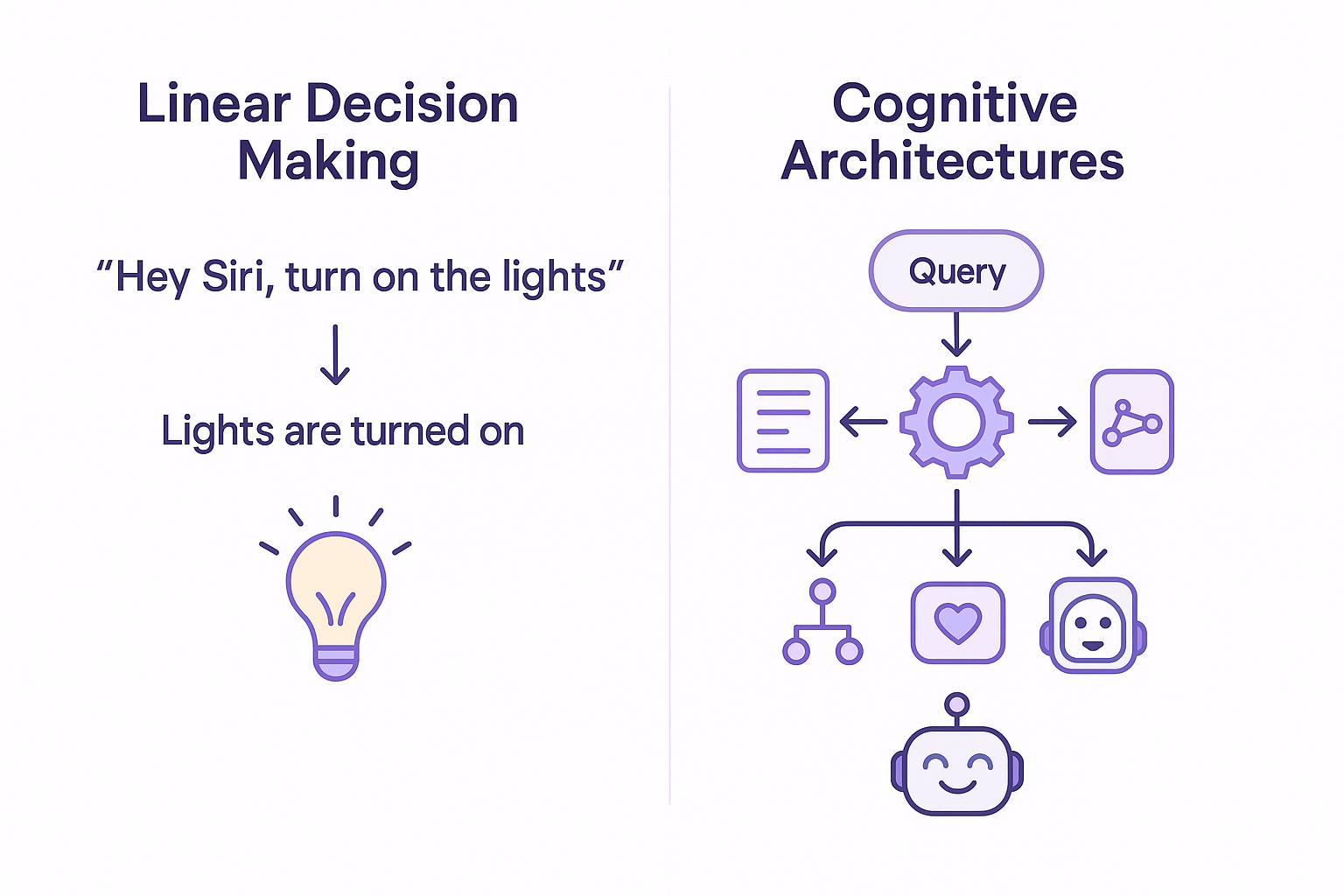
A cognitive architecture is not a single model but a framework for developing chatbots, and various implementations exist. In our latest architecture design, after extensive research, we adopted a cognitive architecture based on the [CoALA architecture][1].
The cognitive architecture is designed to mimic the human brain and its decision-making processes. Many of these elements will be familiar to those with a basic understanding of cognition. Below, we highlight how these components are applied in our demo app, Lost Minute Travel.
Procedural Memory: Procedural memory contains the rules and logic for handling travel-related tasks. This includes both the code that governs interactions with various APIs (e.g., retrieving flight data, checking weather forecasts) and the implicit knowledge within the LLM used to generate travel advice. It ensures consistent processes for trip planning and allows efficient execution of travel-related queries, such as finding flight options or suggesting itineraries based on user preferences.
Semantic Memory: Semantic memory stores factual information relevant to travel planning, such as data about popular destinations, typical weather patterns, and information about attractions and activities. This memory is accessed via our retriever endpoint, which queries relevant knowledge bases and returns the most suitable information for each request. You can read more about our retriever endpoint in the previous blog.
Episodic Memory: Episodic memory keeps a record of past experiences and user interactions. It stores sequences of events, feedback from previous trips, and changes in user preferences over time. This allows the app to learn from experience, offer improved suggestions based on past interactions, and provide a more personalized experience by recalling previous conversations and trip details.
Working Memory: Working memory is a temporary storage area for the app’s current state, including recent user inputs, active goals (like planning a specific trip), and intermediate results from ongoing reasoning processes. It holds the information necessary for the app to process at any moment, such as the user’s current travel query, partial trip plans, and any context needed to continue the conversation. Working memory acts as the central hub, connecting different components of the app’s cognitive architecture.
Decision Procedure: The decision procedure orchestrates the app’s actions. It follows a cycle of proposing, evaluating, and selecting actions based on the information in working memory and long-term memories (episodic, semantic, and procedural). This involves planning, where the app uses reasoning and retrieval to generate and assess actions, such as suggesting destinations or activities based on user preferences and travel dates. The decision procedure ensures the app provides real-time, informed recommendations to help users plan their trips effectively.
We will explore each of these elements and their roles in Lost Minute Travel in more detail in the sections below.
The entire cognitive architecture of our demo app runs on Cloudflare. Specifically, we leverage their Durable Objects product. Durable Objects are essentially workers with built-in storage that automatically move as close as possible to the end user, making them ideal for our architecture. By default, they provide low latency. The built-in storage simplifies the implementation of memory elements, while the built-in compute and access to AI models allow us to run everything else needed for the system.
Though short-lived, Durable Objects integrate with Cloudflare’s KV store, enabling users to easily resume previous conversations. When an older Durable Object is invoked, its constructor automatically loads the latest state of all memory elements, allowing users to pick up their conversations within milliseconds.
The decision procedure is the top-level process that orchestrates the app’s actions. It follows a cycle of proposing, evaluating, and selecting actions based on the information stored in working memory and long-term memories (episodic, semantic, and procedural). This part of the cognitive architecture resembles an agent-based model. However, unlike linear agent systems, our cognitive architecture involves a loop where each step may include multiple cycles of proposing, evaluating, and selecting actions.
When designing a cognitive architecture, we recommend starting with a flowchart of the decision cycle. Mapping out the intended workflow is crucial. For example, our travel architecture mimics the workflow of a human travel agent. Similarly, you can model workflows for support agents, software engineers, sales teams, and more.
During each cycle, the LLM retrieves relevant information from the user’s input and decides which functions to call (e.g., semantic memory, episodic memory, weather API, flights API). It then retrieves and stores information in the appropriate memory store and responds to the user.
Additionally, the decision procedure extracts key details from user input. The primary goal of our travel chatbot is to gather the necessary information to plan a trip. At each step of the process, a minimum set of data is required to move forward. These high-level safeguards ensure the application stays on track to meet its goal.
In most cases, a decision procedure involves both an inner and outer loop. The outer loop manages communication with the user, while the inner loop handles information extraction and decision-making, guiding the user through the defined workflow.
This design helps manage latency. Since the decision cycle may take several seconds to complete, the outer loop keeps the user engaged by explaining what’s happening in the background through LLM-generated responses.
Procedural memory operates within the inner loop of the decision procedure. At a high level, it first evaluates the current state by comparing working memory (our current knowledge) with the guardrails defined in the decision cycle. Each step in the process has its own set of requirements.
For example, the first two stages require the following information (For a full set of the guardrails see the appendix at the end of the article):
To advance from Introduction and Smalltalk to Initial Contact, the name and email must be stored in working memory. If these details are missing, the cognitive architecture will prompt the user to provide them via an LLM-generated response.
While the prompts for each stage are similar, we use distinct prompts tailored to each specific step. This allows for optimized questions suited to the information needed at that stage.
For example, the prompt for Introduction and Smalltalk might look like this:
`You are a helpful travel assistant that helps users plan their next travel.
Currently you have the following information in your working memory. Ask questions to the user to get the missing information:
name: ${this.workingMemory.name}
email: ${this.workingMemory.email}
Your goal is to get the relevant information listed above. Come up with the next
question to ask. Only ask one question at a time. Do not ask questions beyond the scope listed above.
The user is allowed to go off script and ask random questions, but you are not. If you have all information listed above ask the user for their travel dates.
Below is a summary of the chat history with the user so far:
${this.workingMemory.chatHistory}
Additional information to answer the user's question from the semantic search endpoint:
${semanticSearchResults}
Additional information to answer the user's question from the episodic search endpoint:
${episodicSearchResults}
Live data:
Weather: ${weatherData}`
In addition, procedural memory determines which external information is missing and calls the required endpoints to retrieve it. The Lost Minute Travel implementation has access to the following retrieval endpoints:
By using guardrails at each stage, we ensure the user stays on track towards successfully planning their trip. However, the path is not strictly linear. Users can ask unrelated questions at any point, which the cognitive architecture can still handle.
For example, let’s say a user is in the first stage of the cognitive architecture flow, Initial Contact, and they ask:
Hi, I want to plan a trip. I’m thinking about Spain, but I’m not sure where to go, or if the weather is good right now.
Since this question involves Spain and the weather, the procedural memory might decide to:
The response could be something like this:
Hi, nice to meet you! Spain is a fantastic destination with popular spots like Barcelona, Madrid, and Valencia. The current average temperature is around 85°F. To assist you better, could you please provide your name and email?
In addition to guiding the user through the cognitive architecture flow, procedural memory also performs housekeeping tasks. It summarizes the current conversation and stores it in working memory to avoid overwhelming the LLM’s context window and it extracts important details from user input, such as identifying a name or email during the Introduction and Smalltalk stage. If found, it updates the working memory accordingly.
The semantic memory is our main retrieval endpoint for world knowledge (beyond the build-in world knowledge in the LLM). It fetches information we have indexed, including the entirety of Wikipedia and various travel brochures. For a deeper understanding of how this works, you can refer to our blog posts about the indexer and the retriever.
In the context of the cognitive architecture, the key point is that semantic memory returns data as a JSON object. This object includes the relevant semantic chunks of information along with the source URL. The source URL is important, as it enables another technique for hiding latency.
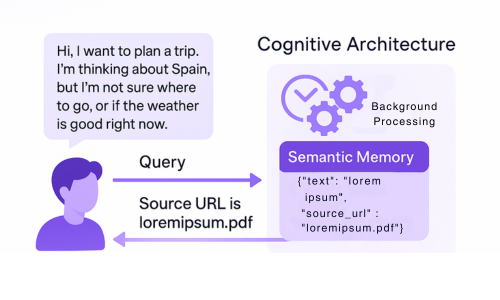
The working memory holds the current state of the world as understood by the cognitive architecture. It includes a variable for each required field in the decision procedure, as well as a summary of the conversation so far.
.png)
Working memory plays a critical role when crafting new responses, guiding the cognitive architecture through the process of trip planning. Our cognitive architecture runs on Cloudflare Durable Objects, which provide built-in storage well-suited for maintaining this type of information. When a user starts a new conversation, we create a new Durable Object using the session ID and initialize an empty working memory object. As the user progresses through the planning process, we continuously update the working memory during the decision cycle.
If the user leaves the conversation and returns later, we can restart the Durable Object using the session ID, allowing the user to pick up where they left off.
Working memory is periodically synced with a D1 database to update user preferences in long-term memory. When a user begins a new conversation, we preload any known information about them into the working memory.
During the decision procedure, the cognitive architecture will confirm this information rather than asking for it again.
For example, in the Needs Assessment stage of the cognitive architecture flow, we focus on the user’s preferences. If we already have this information from a previous conversation, the LLM might ask:
Previously, you mentioned that you don’t enjoy water-related activities. Is that still the case?
Episodic memory provides a simple text-based search, allowing the cognitive architecture to retrieve previous conversations with the user, filtered by date and time. For example, if the user inputs the following:
I want to go back to that one place I visited on March 2nd, 2023.
The decision procedure would likely trigger a search of the episodic memory. It would extract the date, locate the matching conversations, and return relevant information from that past interaction to be incorporated into the new response.
Additionally, we trigger a call to the episodic memory when the user starts a new conversation to load the known information about the user from the D1 database holding the long term memory such as likes and dislikes.
Designing a good cognitive architecture is as much about understanding your business processes and needs as it is about coding. Before starting to build a cognitive architecture, indexer, or retriever, we recommend mapping out the entire workflow of your AI agent. Consider questions like: What is the goal of the agent? What data should it access? What actions should it be able to take?
It’s important to involve subject matter experts in this process. For instance, if you’re designing a cognitive architecture for first-line support, make sure to include your support staff. They handle these tasks daily and know what it takes to excel in their role.
Need assistance? Our team is here to help. We designed Lost Minute as a reference architecture that can be adapted to various use cases with minimal adjustments. Schedule a call to learn more.
The table below shows each stage, the data we aim to retrieve.
| Stage | Data to retrieve |
|---|---|
| Introduction and smalltalk | name, email |
| Initial contact | travel dates, destination, location of user, purpose of travel |
| Needs assessment | travel party size, accommodation preferences, transportation needs, activities, dining preferences, special requests |
| Proposal development/pitch | no data to retrieve but itinerary should be stored on working memory before moving on |
| Adjustments | approval from user to move forward |
| Closing the sale | NA |
Traditional chatbots typically follow rigid, rule-based scripts or simple branching logic. A cognitive architecture mimics human brain functions by incorporating multiple memory systems (procedural, semantic, episodic, and working memory) that work together to process information more fluidly. This allows the system to handle conversations that go off-topic, learn from past interactions, and provide more personalized responses based on accumulated knowledge.
Episodic memory stores past user interactions and preferences, allowing the system to recall specific events and details from previous conversations. This creates a more personalized experience as the system can reference past trips, remember user preferences, and avoid asking for information it already knows. For example, if a user mentioned they dislike water activities in a previous conversation, the system can factor this into future recommendations without asking again.
Yes, cognitive architectures excel at managing complex workflows through their decision procedure component. Unlike linear systems that follow a fixed path, cognitive architectures can process information in loops, evaluate multiple options simultaneously, and adapt to changing user needs. This makes them ideal for complex scenarios like trip planning, where many variables and preferences need to be considered over multiple conversation stages.
Working memory serves as the central hub of a cognitive architecture, temporarily storing and managing information needed for the current conversation. It holds the user’s latest inputs, goals, and contextual information required to generate appropriate responses. Working memory helps maintain conversation coherence by tracking where the user is in the workflow and what information has already been collected, ensuring the system doesn’t lose track during complex interactions.
Implementing a cognitive architecture starts with mapping your business workflow - whether it’s customer support, sales, or specialized services like travel planning. Identify the key stages in your process, the information needed at each stage, and how different types of memory would support these stages. Involve subject matter experts who understand the nuances of customer interactions in your field. The cognitive architecture can then be customized with relevant knowledge bases, APIs, and business logic to create a system that handles your specific use cases effectively.
[1]: Summers et. al. https://arxiv.org/pdf/2309.02427