Rethinking Serverless Series
This is the third blog of the series, Rethinking Serverless, which dives into Raindrop’s Services, Observers, and Actors . You can read up on the full series here:
Yesterday, we explored why dev engineers are drawn to serverless compute, focusing on three compelling advantages: the elimination of server management overhead, automatic scalability that handles traffic spikes without manual intervention, and cost efficiency through pay-per-execution pricing models. These benefits have made serverless a go-to choice for many development teams.
The decision between stateful and stateless approaches isn’t just technical minutiae; it fundamentally shapes how your applications handle data persistence, user sessions, and long-running processes. Understanding these patterns will help you leverage those same three serverless benefits we discussed previously while navigating a core challenge that has persisted throughout serverless adoption.
But as we dive into the third and final blog in this serverless series, we need to examine a critical architectural consideration that can make or break your serverless strategy: the choice between stateful and stateless compute patterns. Today, we’ll explore, in depth, one fundamental limitation that has kept serverless from reaching its full potential: functions that forget everything between requests.
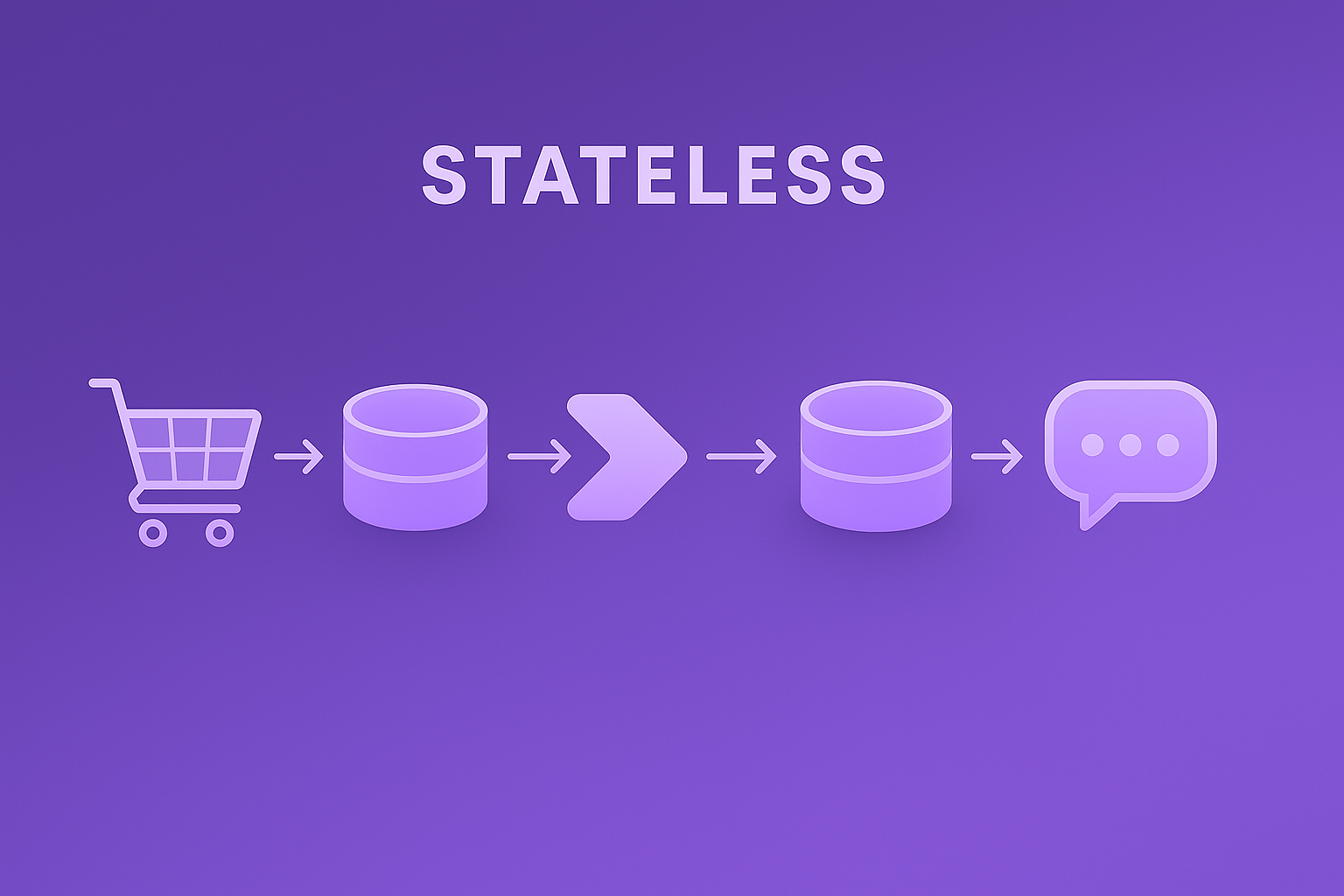
Traditional serverless functions are completely stateless. Every request starts from scratch—no memory of previous interactions, no way to maintain user sessions, no coordination between related requests. Need to track a user’s shopping cart? You’ll need an external database. Want to implement rate limiting per user? More external storage. Building a chat room or collaborative feature? Prepare for complex state synchronization.
This stateless design forces developers to add databases, caches, and external state stores for even simple use cases, or the state management between requests is an exercise left up to the developer.
Actors in Raindrop are stateful compute units that maintain persistent data and handle requests with a unique identity. Unlike stateless services that lose data between requests, each actor instance remembers its state and can coordinate complex workflows over time.
Think of actors as persistent “mini-services”—each user session, shopping cart, or game room can be its own actor instance. When a request comes in, you route it to the specific actor by ID, and that actor maintains all the relevant state for that user, cart, or room.

Actors complete Raindrop’s three-pillar approach to modern serverless development:
Let’s dive into how Actors can be used to make your life easier.
Each actor instance maintains its own storage that persists between requests. No external databases needed for simple state management—the storage is built right into the actor.
Every actor has a unique ID that allows you to route related requests to the same instance. User sessions, shopping carts, chat rooms—each gets its own actor that maintains all the relevant state.
Actors can schedule operations to run in the future. Perfect for implementing timeouts, session expiration, cleanup tasks, or any time-based logic.
Each actor instance is completely isolated from others. One user’s shopping cart actor can’t interfere with another’s, ensuring data integrity and security.
// in your raindrop.manifest file
application "shopping-app" {
service "api" { domain { cname = "shop-api" } }
actor "shopping-cart" {}
}
// in your index.ts file
export class ShoppingCartActor extends Actor<Env> {
async addItem(productId: string, quantity: number): Promise<Response> {
// Get current cart items from persistent storage
const items = await this.state.storage.get<CartItem[]>("items") || [];
// Add new item
items.push({ productId, quantity, addedAt: Date.now() });
// Save back to persistent storage
await this.state.storage.put("items", items);
// Schedule cart cleanup for 24 hours from now
await this.state.storage.setAlarm(Date.now() + 24 * 60 * 60 * 1000);
return new Response(JSON.stringify({
success: true,
itemCount: items.length
}));
}
async alarm(): Promise<void> {
// Automatically called when alarm triggers// Clean up expired cart
await this.state.storage.delete("items");
}
}
Services act as the public gateway to your actors. When a request comes in, the service determines which actor instance should handle it and calls the appropriate method on that actor.
// in your index.ts file
// Service routes requests to user-specific actors
export default class extends Service<Env> {
async fetch(request: Request): Promise<Response> {
const userId = getUserIdFromRequest(request);
const productId = getProductIdFromRequest(request);
// Route to user-specific shopping cart actor
const actorId = this.env.SHOPPING_CART.idFromName(userId);
const actor = this.env.SHOPPING_CART.get(actorId);
// Call custom actor method (not fetch)
return await actor.addItem(productId, 1);
}
}
Each user gets their own shopping cart actor instance that remembers their items across requests. No external database required for this simple state management.
User Sessions and Authentication State: Each user gets their own session actor that tracks login status, permissions, and temporary data.
Shopping Carts and Temporary User Data: Store items, preferences, and checkout progress that persists across browser sessions.
Chat Rooms and Collaborative Spaces: Each room is an actor that maintains participant lists, message history, and room settings.
AI Agents and Autonomous Systems: Create persistent AI agents that maintain context, memory, and state between interactions, enabling complex reasoning and long-term planning capabilities.
Workflow Coordination: Multi-step processes like order fulfillment, approval workflows, or data processing pipelines.
Rate Limiting and User-specific Counters: Track API usage, download limits, or any per-user metrics without external storage.

Actors provide a rich API for managing persistent state:
All storage operations are atomic and consistent, ensuring your actor’s state remains reliable even under high concurrency.
Combine all three Raindrop components for complete applications:
// in your raindrop.manifest file
application "collaborative-platform" {
// Public API layer
service "api" { domain { cname = "collab-api" } }
// Internal services for business logic
service "auth" {}
service "notifications" {}
// Stateful components
actor "user-session" {}
actor "document" {}
actor "chat-room" {}
// Define your bucket
bucket "documents" {}
// Event processing
observer "document-processor" {
source { bucket = "documents" }
rule {
// Specify which actions should trigger the observer
actions = ["PutObject", "CopyObject", "CompleteMultipartUpload"]
}
}
// Background tasks
queue "email-jobs" {}
observer "email-sender" {
source { queue = "email-jobs" }
}
}
Your API service handles requests and routes them to appropriate actors. User sessions track authentication state, document actors maintain collaborative editing state, and chat room actors coordinate real-time conversations. Observers process document uploads and send notifications asynchronously.
Actors scale automatically based on demand and hibernate when not in use. The built-in alarm system handles cleanup, session expiration, and any time-based operations without additional infrastructure.
You get the benefits of stateful applications—persistent sessions, real-time features, and complex workflows—without the operational overhead of managing state stores, databases, or cleanup processes.
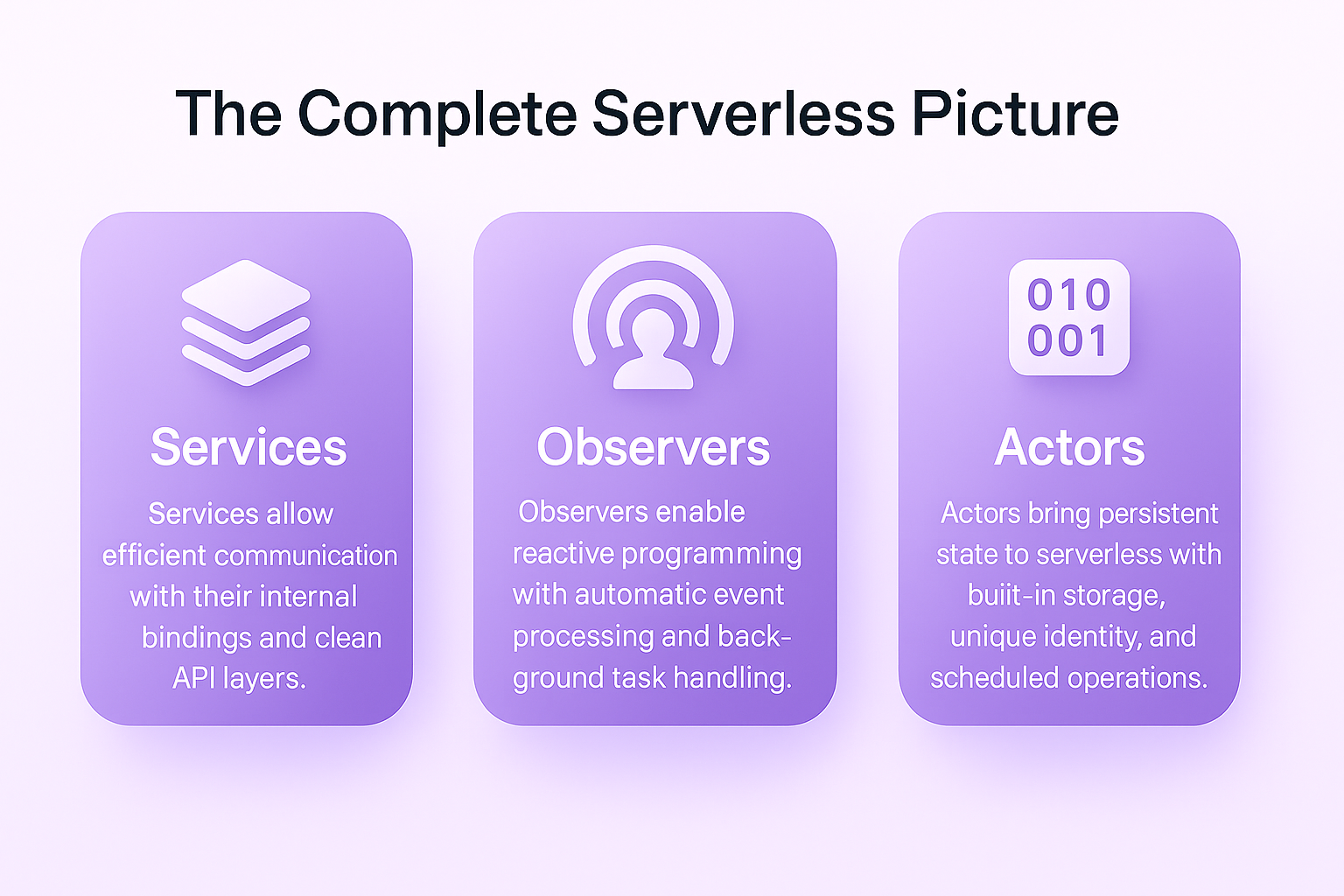
We’ve now explored all three pillars of modern serverless development in Raindrop:
Services solve the communication problem with efficient internal bindings and clean API layers.
Observers enable reactive programming with automatic event processing and background task handling.
Actors bring persistent state to serverless with built-in storage, unique identity, and scheduled operations.
Together, these components form a complete platform for building applications that were near impossible with traditional serverless architectures. You can now build everything from simple APIs to complex, stateful, real-time collaborative applications—all with the serverless benefits of automatic scaling, cost efficiency, and zero server management.
Ready to build stateful serverless applications? Check out the complete Actors documentation and start building applications that remember.
The future of serverless development includes persistent state, reactive event processing, and efficient inter-service communication. With Services, Observers, and Actors, that future is available today.
Ready to make your data smarter with your own AI agents? We’re offering:
✨ Free 2 million tokens and 10GB of storage per month
💰 Pay-as-you-go for additional tokens and storage
🎯 No egress fees
Want to explore costs first? Take a look at our pricing here. To get in contact with us or for more updates, join our Discord community.