Rethinking Serverless Series
This is the first blog of the series, Rethinking Serverless, showcasing Raindrop’s Services, Observers, and Actors. You can read up on the full series here:
Dev engineers who love serverless compute often highlight these three top reasons:
But what if the very isolation that makes serverless appealing also hinders its potential for intricate, multi-component systems?
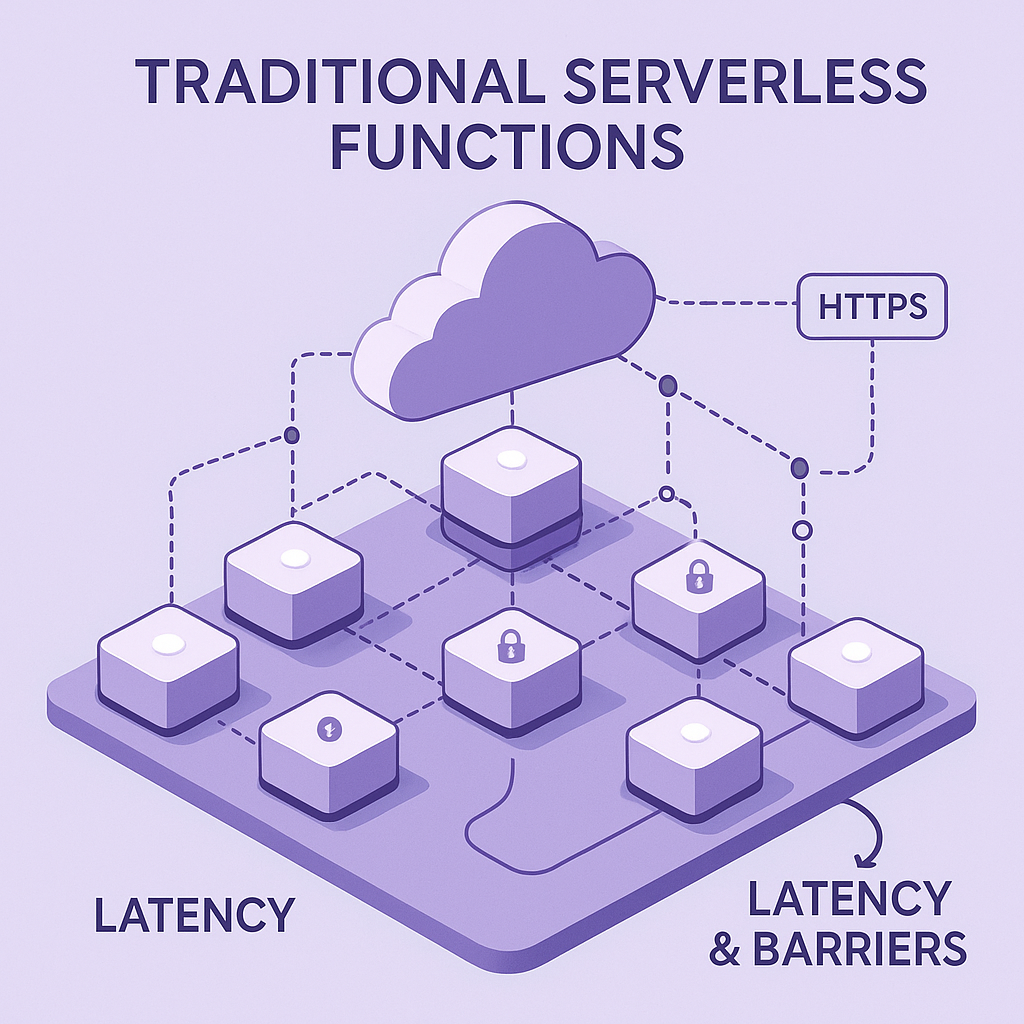
Traditional serverless functions are islands. Each function handles a request, does its work, and forgets everything. Need one function to talk to another? You’ll be making HTTP calls over the public internet, managing authentication between your own services, and dealing with unnecessary network latency for simple internal operations.
This architectural limitation has held back serverless adoption for complex applications. Why would you break your monolith into microservices if it means every internal operation becomes a slow, insecure HTTP call, and/or any better way of having communications between them is an exercise completely left up to the developer?
Services in Raindrop are stateless compute blocks that solve this fundamental problem. They’re serverless functions that can work independently or communicate directly with each other—no HTTP overhead, no authentication headaches, no architectural compromises.
Think of Services as the foundation of a three-pillar approach to modern serverless development:
Let’s dive into how Services can be used to make your life easier.
Public services are exactly what you’d expect—serverless functions accessible via unique URLs. They handle external requests, manage authentication, and serve as entry points to your application.
// raindrop.manifest
service "my-api" {
domain {
cname = "my-unique-service"
}
}
When deployed, this service becomes accessible at my-unique-service.<org-id>.lmapp.run. Perfect for APIs, webhooks, and any user-facing functionality.
Here’s where things get interesting. Internal services don’t need public URLs—they’re designed to be called by other services within your application. But unlike traditional serverless functions, they can be invoked directly without HTTP calls.
This is service binding in action: efficient, secure communication between your services without the networking overhead.
// raindrop.manifest
service "my-api" {}
The magic happens when services call each other. Instead of making HTTP requests, services invoke methods directly on other services. It’s like having a private, high-speed network between your functions. Below are the public and internal services in action:
// Service A (public-facing)
export default class extends Service<Env> {
async fetch(request: Request): Promise<Response> {
// Direct call to internal service - no HTTP, no URLs needed
const response = await this.env.SERVICE_B.processData({
userId: getUserId(request)
});
return response;
}
}
// Service B (internal-only)
export default class extends Service<Env> {
async processData(input: any): Promise<Response> {
// Your business logic here
return new Response("Processed successfully");
}
}
Notice what’s missing? No URLs, no authentication headers, no HTTP status code handling between your own services. Service A calls a method on Service B as naturally as calling any other function, but with all the benefits of independent scaling and deployment.
With service bindings, you can structure applications the way they should be structured: with clear separation between public interfaces and internal business logic.
application "store" {
// Public-facing services
service "api" { domain { cname = "store-api" } }
service "admin" { domain { cname = "admin-panel" } }
// Internal services
service "inventory" {}
service "payments" {}
service "notifications" {}
}
Your public API service handles incoming requests, validates input, and coordinates with internal services for inventory checks, payment processing, and notifications. Each service has a single responsibility, scales independently, and can be updated without affecting the others.
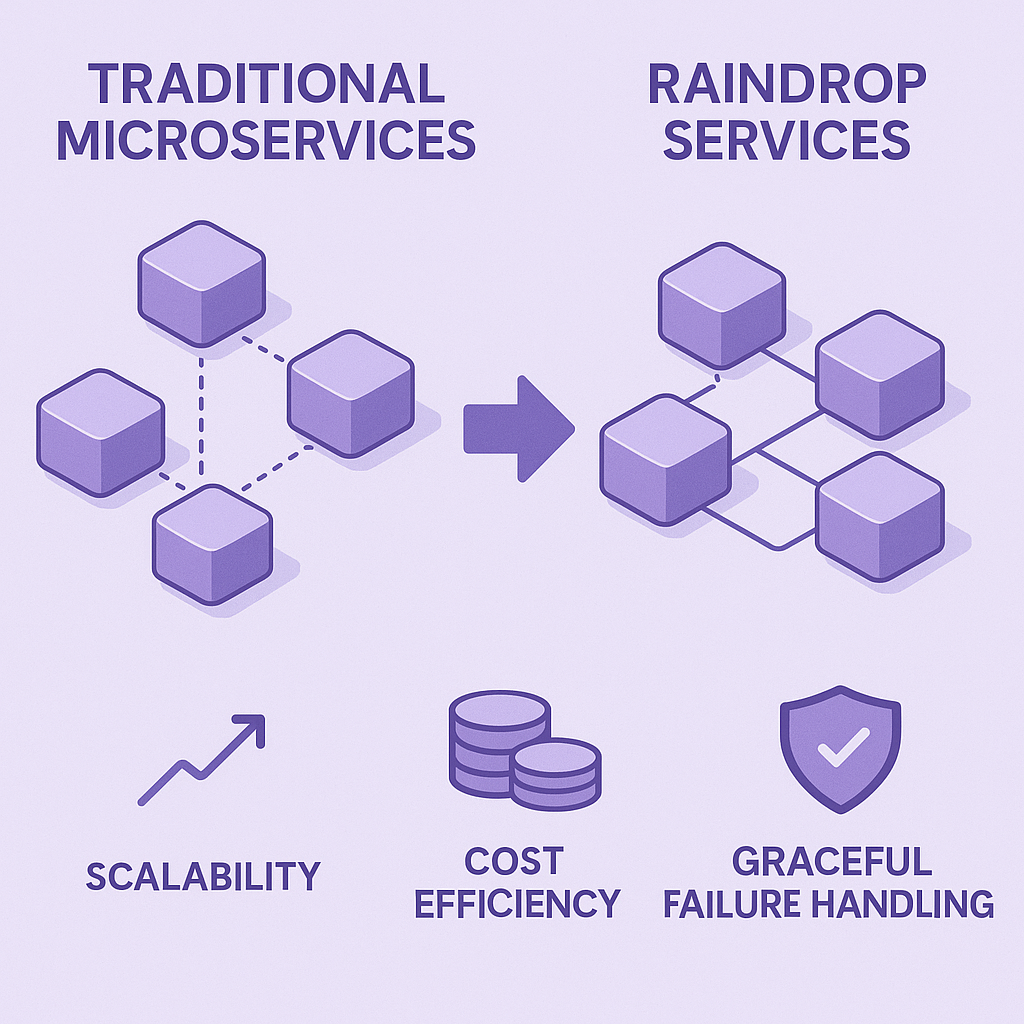
Traditional microservices require service discovery, load balancing, and complex networking. With Raindrop Services, all of that is handled automatically. Your services discover each other through the manifest configuration, calls are automatically load-balanced, and the platform handles failures gracefully.
You get the benefits of microservices—independent scaling, ease of deployment, and paying for what you use only—without the operational overhead.
Services solve the fundamental communication problem in serverless architectures, but they’re just the beginning. Modern applications need more than request-response patterns—they need to react to events and maintain state across requests.
Part 2 - Observers (coming soon): Learn how to build reactive applications that respond to changes automatically:
Part 3 - Actors (following): Discover stateful serverless computing:
Together, Services, Observers, and Actors form a complete platform for building applications that were near impossible with traditional serverless architectures.
Ready to experience serverless functions that actually work together? Check out the complete Services documentation and start building applications the way they should be built.
In our next post, we’ll explore how Observers let you build reactive applications that respond to changes automatically—no polling, no complex event systems, just clean, efficient event-driven code.
Ready to make your data smarter with your own AI agents? We’re offering:
✨ Free 2 million tokens and 10GB of storage per month
💰 Pay-as-you-go for additional tokens and storage
🎯 No egress fees
Want to learn more? Check out our documentation for more details.
Want to explore costs first? Take a look at our pricing here. To get in contact with us or for more updates, join our Discord community.