In the midst of the buzz surrounding large language models (LLMs), one term that has emerged is retrieval augmented generation (RAG). This article aims to provide a clear perspective on retrieval augmented generation, shedding light on its definition, practical applications, limitations, and potential for the future of generative AI and natural language processing.
Retrieval augmented generation is an approach to teaching pre-trained language models new information without expensive fine-tuning. This becomes particularly important when considering the staggering computational and financial costs associated with training large language models from scratch or updating their training data.
For instance, GPT-4, a popular language model, is said to have incurred a mind-boggling cost of approximately $100 million. While this might be mere pocket change for well-funded companies such as OpenAI, backed by tech juggernaut Microsoft, it remains an insurmountable barrier for most organizations. Fortunately, RAG can enable us to teach pre-trained language models new information using external data sources without these prohibitive financial costs. Who said you couldn’t teach an old dog new tricks?!
The retrieval augmented generation approach involves presenting the AI model with a collection of relevant information, followed by a prompt about that information. This technique is particularly valuable for concepts previously unknown to the language model or for retrieving up-to-date information from external knowledge bases. Let’s look at a simple example. We first introduce the language model to a set of category examples and subsequently prompt it to categorize an unfamiliar sample using the newly acquired category system.
PROMPT: car = category 1, bike = category 2, skateboarding = category 2, truck = category 1, cycling = category 2. Which category belongs to rollerblading?
Output: Rollerblading is in the same category as skateboarding which is in category 2.
For the trained eye, we separated the categories by motor-based and human-powered vehicles. While this is a completely made-up example, the language model accurately picked the category without retraining the model or requiring fine-tuning because it could process the relevant information provided in the initial prompt.
You could argue that the language model already had some knowledge about rollerblading and skateboarding, causing it to group them together based on their shared semantic meaning instead of recognizing them as distinct forms of human-powered transportation. Nevertheless, it did manage to place them in the correct category based on semantic similarity and the relevant context.
While this is a simple example, the potential for extending retrieval augmented generation to a larger scale example should not be overlooked. For example, if your company uses an internal documentation system, such as Google Docs, Notion, Jira, or any other knowledge bases, chances are you’ve experienced the phenomenon of these systems gradually evolving into information black holes sucking the life out of your productivity.
While that might sound discouraging, with the help of language models, we can transform those information repositories into a Chat-GPT-style platform trained on your internal knowledge base using natural language processing techniques.
By inputting relevant information from the repository into the language model (this is our retrieval augmented generation step), you can ask it any question you like and get meaningful answers that are more accurate than relying solely on the model’s training data. This process enables AI models to answer questions with factual accuracy even when the information wasn’t part of their original training.
For example, if you include the most relevant documents as context, the language model can easily answer questions like, “What’s our strategy for introducing new products?” or “When do we usually publish new blog posts?” It can answer any question you like as long as the answers live somewhere in that treasure trove of internal documentation and you can retrieve relevant information efficiently using semantic search or hybrid search technology.
However, this approach has two main problems, and the remainder of this blog will offer solutions to these common issues in RAG systems.
First of all, providing the language model with all the information stored in your knowledge repository decreases the chances of it delivering accurate responses. To illustrate, if only about 1% or even less of the documents you input are truly relevant, then the chances of getting inaccurate responses are significantly higher. Effective document retrieval is essential to avoid this problem.
Secondly, most, if not all, language models are limited by context window size. This essentially means there’s a cap on the amount of input they can handle. For instance, GPT-3.5 has a context window of 4,000 tokens, which translates to approximately 5,000 words. Although this might seem substantial, it’s highly unlikely to be enough to accommodate your entire company’s knowledge base or the entirety of relevant data points.
Luckily there is a solution, vector databases and semantic search!
Retrieval augmented generation does come with its share of challenges, particularly when it comes to the context window restriction of language models. However, there’s a potential solution in the form of vector databases. But before we dive into this solution, let’s take a quick moment to understand what vector databases are, how they function, and how we can leverage them for RAG purposes with various data sources and knowledge bases.
Vector databases, as the name might suggest, store vectors - the mathematical representations of text and other data; you know those pesky things you had to learn about for your linear algebra class?
Putting humor aside, the integration of vector databases with vector embeddings (a method for converting text into numerical representations) offers a great way of transforming and storing vector representations of our knowledge repository. You might be familiar with popular tools such as Pinecone, Quadrant, ChromaDB, Vectorize by Cloudflare etc. that provide vector search capabilities.
By transforming our unstructured data into vectors and housing them within a vector database, we can tap into a range of useful possibilities. For example, we can now employ search algorithms such as k-nearest neighbor (KNN) and other methods to run similarity searches between user queries and our documents. This semantic search approach is far more effective than traditional keyword search for retrieving relevant information.
This approach has the potential to tackle the two issues RAG systems and language models have to overcome. Instead of overwhelming the language model with our entire knowledge repository, we can now selectively feed it the most relevant documents i.e. KNN, where K=7 will only return the seven most relevant documents. This resolves the problem of context window size and ensures that the language model is exposed only to materials that are truly relevant for generating responses and creating an engaging answer tailored to the user input.
A retrieval augmented generation pipeline utilizing a vector database might look something like this.
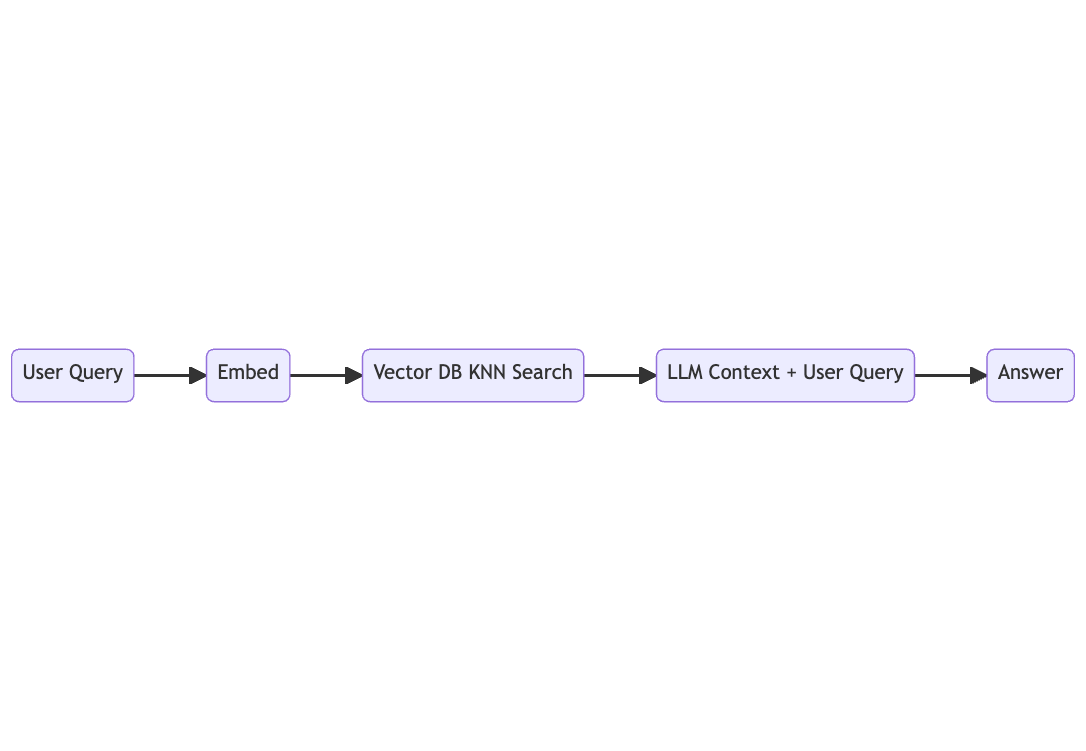
In step one, the user inputs their query. The user query is embedded using the same embeddings that were used to turn all documents into vectors. A similarity search is run inside the vector database to get the K most similar documents. The output of the search + the initial prompt is sent to the language model where we ask it to form the final answer.
Answer this question : [query] based on this information [most relevant documents].
This approach has a couple of notable advantages. Most importantly, we can send only the relevant information to the language model for processing. Reducing the need for very large context windows and improving factual accuracy through structured data retrieval.
Using vector databases and any language model enables anyone to build their own chat GPT on private data without spending millions on training data and fine-tuning models. You can leverage your existing knowledge bases and data sources to create powerful AI applications without extensive machine learning expertise.
Retrieval augmented generation is a great tool to build generative AI applications on your data sources as long as you have access to a vector database, a platform to create embeddings, and a language model (which you might have guessed are all included in the Cloudflare platform). This combination forms the foundation of how retrieval augmented generation works in an enterprise setting.
As we mentioned earlier, a key motivation for utilizing a vector database in the context of retrieval augmented generation is to trim down the size of your input queries. However, if you’ve been following developments in the field of language models, you’ve likely noticed a continuous expansion of the context window of these AI models and their ability to process new data.
For instance, while GPT-3.5 started with a context window of 4096 upon its initial release, the latest iteration, GPT-4, supports 32,768. Even more impressively, there are already open-source language models with even larger context windows, such as Claude 3, which supports an astonishing 100K context window.
Given that these model context windows are doubling at an almost exponential rate (a nod to Moore’s law), you might naturally wonder whether a vector database is still needed for retrieval augmented generation much longer in the world of generative AI and if semantic search will remain important as circumstances evolve.
While it’s challenging to predict the exact future capabilities of these AI models, we think that vector databases will continue to play a significant role in the domain of retrieval augmented generation, and there are several reasons why they remain crucial for information retrieval in AI applications.
For starters, commercial language models are likely to continue to charge based on the number of tokens used. Meaning it’s in your wallet’s best interest to minimize the length of your queries to control financial costs. A simple vector search can be a valuable tool. Reducing the input prompt can make the difference between a $1K monthly bill and a $10K monthly bill when using generative AI models.
Furthermore, even though providing a lot of context often leads to better language model performance, there’s a limit to its effectiveness. Overloading your language model with excessive information might eventually lead to a worse reply. Increasing the relevance of your input query using vector databases and hybrid search will only strengthen the output. Remember the old saying garbage in garbage out, it still applies today even with the most advanced search engine technology!
Retrieval augmented generation enhances language models by feeding them relevant information at query time, without changing the model’s parameters. Fine-tuning, on the other hand, involves actually updating the model’s weights through additional training data. RAG is typically faster, cheaper, and allows you to incorporate new data sources without retraining, while fine-tuning can be more effective for specialized tasks but requires more computational resources.
Vector databases improve RAG by storing and efficiently retrieving relevant documents based on semantic similarity rather than just keyword search. They convert text into mathematical representations (vectors) that capture meaning, allowing the system to quickly find the most relevant information from large knowledge bases when responding to a user query. This approach helps retrieve data that is conceptually related, not just exact matches.
Yes, retrieval augmented generation can work with virtually any type of data sources that can be converted to text or embeddings. This includes structured data (databases, spreadsheets), unstructured data (documents, emails, websites), and semi-structured data (JSON, XML). The key requirement is that the data can be converted into vector embeddings for storage in a vector database, enabling effective semantic search capabilities.
Some limitations of retrieval augmented generation include: dependency on the quality of the retrieval system, potential challenges with very specialized or technical domains, limitations in handling information that changes frequently without regular updates to the knowledge base, and the need for efficient vector search to avoid slowing down response times. Additionally, RAG systems still require careful design to avoid retrieving irrelevant or misleading information that could lead to inaccurate responses.
Businesses can implement retrieval augmented generation by first identifying relevant data sources (internal documents, knowledge bases, etc.), converting this information into vector embeddings, storing these in a vector database, and connecting this system to a language model. When users ask questions, the system retrieves relevant information from the vector database and feeds it to the language model along with the query, resulting in more accurate and contextually relevant responses for search engines, customer support, or internal knowledge management. This approach lets you build powerful AI applications without the significant financial costs of developing specialized language models.
Semantic search is a critical component of effective retrieval augmented generation systems. Unlike traditional keyword search that matches exact terms, semantic search understands the meaning and intent behind queries, allowing it to find relevant documents even when they use different terminology. In RAG systems, semantic search helps identify the most relevant information from knowledge bases to provide as context to the language model, significantly improving the accuracy of generated responses without requiring extensive training data or web pages indexing.